Submitted by C. Barry Pfitzner, Steven D. Lang and Tracy D. Rishel
ABSTRACT
In this paper we attempt to predict the total points scored in National Football League (NFL) games for the 2010-2011 season. Separate regression equations are identified for predicting points for the home and away teams in individual games based on information known prior to the games. The sum of the predictions for the home and away teams computed from the regression equations (updated weekly) are then compared to the over/under line on individual NFL games in a wagering experiment to determine if a successful betting strategy can be identified. All predictions in this paper are out-of-sample—meaning that all of the information necessary for the predictions was available before the games were played. Using this methodology, we find that several successful wagering strategies could have been applied to the 2010-2011 NFL season. We also estimate a single equation to predict the over/under line for individual games. That is, we test to see if the variables we have collected and formulated are important in predicting the betting line for NFL games. These results can be used by either bettors or bookmakers wanting to increase their odds of success in the gaming industry.
INTRODUCTION
Bookmakers set over/under lines for virtually all NFL games. Suppose the over/under line for total points in a particular game is 40. Suppose further that a gambler wagers with the bookmaker that the actual points scored in the game will exceed 40, that is, he bets the “over.” If the teams then score more than 40 points, the gambler wins the wager. If the teams score under 40 points, the gambler loses the bet. If the teams score exactly 40 points, the wager is tied and no money changes hands. The process works symmetrically for bets that the teams will score fewer than 40 points, or betting the “under.” The over/under line differs, of course, on individual games. Since losing bets pay a premium (often called the “vigorish,” “vig,” or “juice” and typically equal 10%), the bookmakers will profit as long the money bet on the “over” is approximately equal to the amount of money bet on the “under” (bookmakers also sometimes “take a position,” that is, they will welcome unbalanced bets from the public if the bookmaker has strong feelings regarding the outcome of the wager [see also the reference to Levitt’s work in the literature review]). It is widely known a gambler must win 52.4% of the wagers to be successful. That particular calculation can be established simply. Let Pw = the proportion of winning bets and (1 – Pw ) = the proportion of losing bets. The equation for breaking even on such bets where every winning wager nets $10 and each losing wager represents a loss of $11 is:
Pw ($10) = (1 – Pw ) ($11) , and solving for Pw
Pw = 11∕21 = .5238, or approximately 52.4%
This research attempts to identify methods of predicting the total points scored in a particular game based on information available prior to that game. The primary research question is whether or not these methods can then be utilized to formulate a successful gambling strategy for the over/under wager, with success requiring a winning percentage of at least 52.4%.
The remainder of this paper is organized as follows: in the next section we describe the efficient markets hypothesis as it applies to the NFL wagering market; we then offer a brief review of the literature; in the following section we describe the data and method; descriptive statistics and the main regression results are then presented; these are followed by the wagering simulations; we next discuss our investigation of the determinants of the over/under line; and finally offer our conclusions.
NFL Betting as a Test of the Efficient Markets Hypothesis
A number of important papers have treated wagering on NFL games as a test of the Efficient Market Hypothesis (EMH). This hypothesis has been widely studied in economics and finance, often with focus on either stock prices or foreign exchange markets. Because of the difficulties of capturing EMH conclusions given the complexities of those markets, some researchers have turned to the simpler betting markets, including sports (and the NFL), as a vehicle for such tests.
If the EMH holds, asset prices are formed on the basis of all information. If true, then the historical time series of such asset prices would not provide information that would allow investors to outperform the naïve strategy of buy-and-hold (see, for example, Vergin 2001). As applied to NFL betting, if the use of past performance information on NFL teams cannot generate a betting strategy that would exceed the 52.4% win criterion, the EMH hypothesis holds for this market. Thus, the thrust of much of the research on the NFL has taken the form of attempts to find winning betting strategies, that is, strategies that violate the weak form of the EMH.
A Brief Review of the Recent Literature
Nearly all of the extant literature on NFL betting uses the point “spread” as the wager of interest. The spread is the number of points by which one team (the favorite) is favored over the opponent (the underdog). Suppose team A is favored over team B by 7 points. A wager on team A is successful only if team A wins by more than 7 points (also known as “covering” the spread). Symmetrically, a wager on team B is successful only if team B loses by fewer than 7 points or, of course, team B wins or ties the game—in any of these cases, team B “covers.” Vergin (2001) and Gray and Gray (1997) are examples of research that focus on the spread.
Based on NFL games from 1976 to 1994, Gray and Gray (1997) find some evidence that the betting spread is not an unbiased predictor of the actual point spread on NFL games. They argue that the spread underestimates home team advantage, and overstates the favorite’s advantage. They further find that teams who have performed well against the spread in recent games are less likely to cover in the current game, and those teams that have performed poorly in recent games against the spread are more likely to cover in the current game. Further Gray and Gray find that teams with better season-long win percentages versus the spread (at a given point in the season) are more likely to beat the spread in the current game. In general, they conclude that bettors value current information too highly, and conversely place too little value on longer term performance. That conclusion is congruent with some stock market momentum/contrarian views on stock performance. Gray and Gray then use the information to generate probit regression models to predict the probability that a team will cover the spread. Gray and Gray find several strategies that would beat the 52.4% win percentage in out-of-sample experiments (along with some inconsistencies). They also point out that some of the advantages in wagering strategies tend to dissipate over time.
Vergin (2001), using data from the 1981-1995 seasons, considers 11 different betting strategies based on presumed bettor overreaction to the most recent performance and outstanding positive performance. He finds that bettors do indeed overreact to outstanding positive performance and recent information, but that bettors do not overreact to outstanding negative performance. Vergin suggests that bettors can use such information to their advantage in making wagers, but warns that the market and therefore this pattern may not hold for the future.
A paper by Paul and Weinbach (2002) is a departure from the analysis of the spread in NFL games. They (as do we in this paper) target the over/under wager, constructing simple betting rules in a search for profitable methods. These authors posit that rooting for high scores is more attractive than rooting for low scores. Ceteris paribus, then, bettors would be more likely to choose “over” bets. Paul and Weinbach show that from 1979-2000, the under bet won 51% of all games. When the over/under line was high (exceeded the mean), the under bet won with increasing frequency. For example, when the line exceeded 47.5 points, the under bet was successful in 58.7% of the games. This result can be interpreted as a violation of the EMH at least with respect to the over/under line.
Levitt (of Freakonomics fame) approaches the efficiency question from a different perspective. It is clear that if NFL bets are balanced, the bookmaker will profit by collecting $11 for each $10 paid out. As we suggested earlier, bookmakers at times take a “position” on unbalanced bets, on the assumption that the bookmaker knows more about a particular wager than the bettors. Levitt presents evidence that the spread on games is not set according to market efficiency. For example, using data from the 2001-2002 seasons, he shows that home underdogs beat the spread in 58% of the games, and twice as much was bet on the visiting favorites. Bookmakers did not “move the line” to balance these bets, thus increasing their profits as the visiting favorite failed to cover in 58% of the cases.
Dare and Holland (2004) re-specify work by Dare and MacDonald (1996) and Gray and Gray (1997) and find no evidence of the momentum effect suggested by Gray and Gray, and some, but less, evidence of the home underdog bias that has been consistently pointed out as a violation of the EMH. Dare and Holland ultimately conclude that the bias they find is too small to reject a null hypothesis of efficient markets, and also that the bias may be too small to exploit in a gambling framework.
Still more recently, Borghesi (2007) analyzes NFL spreads in terms of game day weather conditions. He finds that game day temperatures affect performance, especially for home teams playing in the coldest temperatures. These teams outperform expectations in part because the opponents were adversely acclimatized (for example, a warm weather team visiting a cold weather team). Borghesi shows this bias persists even after controlling for the home underdog advantage.
METHODS
We focus on the total points scored in NFL games and the corresponding over/under line for that game. With the objective of estimating regression equations for home and away team scoring, data were gathered for the 2010-11 season for the analysis. The variables include:
TP = total points scored for the home and visiting teams for each game played
PO = passing offense in yards per game
RO = rushing offense in yards per game
PD = passing defense in yards per game
RD = rushing defense in yards per game
GA = “give aways,” offensive turnovers per game
TA = “take aways,” defensive turnovers per game
D = a dummy variable equal to 1 if the game is played in a closed dome, 0 otherwise
PP = points scored by a given team in their prior game
L = the over/under betting line on the game
Match-ups Matter (we think)
The general regression format is based on the assumption that “match ups” are important in determining points scored in individual games. For example, if team “A” with the best passing offense is playing team “B” with the worst passing defense, ceteris paribus, team “A” would be expected to score many points. Similarly, a team with a very good rushing defense would be expected to allow relatively few points to a team with a poor rushing offense. In accord with this rationale, we formed the following variables:
PY = PO + PD = passing yards
RY = RO + RD = rushing yards
For example, suppose team “A” is averaging 325 yards (that’s high) per game in passing offense and is playing team “B” which is giving up 330 yards (also, of course, high) per game in passing defense. The total of 655 would predict many passing yards will be gained by team “A,” and likely many points will be scored by team “A.”
Similarly, we theorize that if a team’s offense that commits many turnovers plays a team whose defense causes many turnovers, points scored for the offensive team may be lower (and perhaps more points will be scored by the defensive team). For turnovers, we created variables similar to the passing and rushing yards in the previous paragraph:
TO = GA + TA, that is, turnovers = “give aways” for a given team plus “take aways” for the opposition team.
The dome variable will be a check to see if teams score more (or fewer) points if the game is played indoors.
The variable for points scored in the prior game (PP) is intended to check for streakiness in scoring. That is, if a team scores many (or few) points in a given game, are they likely to have a similar performance in the ensuing game?
We also test to ascertain whether or not scoring is contagious. That is, if a given team scores many (or few) points, is the other team likely to score many (or few) points as well? We test for this by two-stage least squares regressions in which the predicted points scored by each team serve as explanatory variables in the companion equation.
General Regression Equations
The general sets of regressions attempted are of the form:
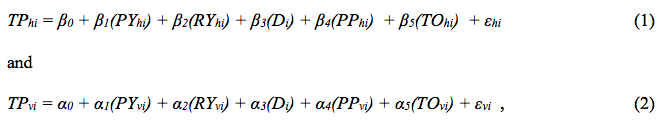 where the subscripts h and v refer to the home and visiting teams respectively, and the i subscript indicates a particular game.
where the subscripts h and v refer to the home and visiting teams respectively, and the i subscript indicates a particular game.
Equations such as 1 and 2 are estimated using data for weeks 5 through 17 of the 2010-11 season. We chose to wait until week five to begin the estimations so that statistics on offense, defense, turnovers, etc., are more reliable than would be the case for earlier weeks.
RESULTS AND DISCUSSION
Descriptive Statistics
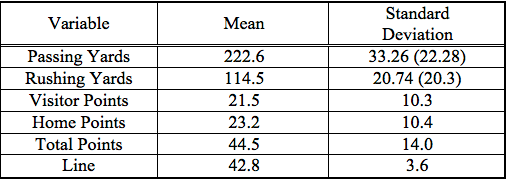
Table I contains some summary statistics for the data set. Teams averaged approximately 223 yards passing per game (offense or defense, of course) for the season, and they averaged approximately 115 yards rushing. The statistics reported on the rushing and passing standard deviations without parentheses are for the offenses and the defensive standard deviations are (as you might guess) in parentheses. Interestingly, passing defense is less variable across teams than is passing offense (we hypothesize that teams must be more balanced on defense to keep other teams from exploiting an obvious defensive weakness, but teams may be relatively unbalanced offensively and still be successful [see the 2011 Packers, for example, who ranked near the top in passing offense and near the bottom in rushing defense]). Home teams scored approximately 23.2 points on average for the season and outscored the visitors by 1.7 points. Total points averaged 44.5 in 2010-2011 and the over/under line averaged 42.8 (the difference between these means is statistically significant at α < .10; the calculated value for the t-test of paired samples is approximately 1.92). Not surprisingly, the standard deviation was much smaller for the line than for total points.
Table I: Summary Statistics
Regression Results
Though equations 1 and 2 from above represent our theoretical foundation, we did not find empirical support for the dome effect, points scored in the prior game, or for turnovers in predicting points for either the home or away teams. Thus we do not report regressions with those variables included (such estimations are available from the authors upon request). Since our objective is to produce predictions based on variables (and their effects) that are known prior to the games, we updated the equations weekly and checked for effects for those excluded variables. We did not find convincing evidence that any of the excluded variables should be included in the predictive equations.
The dome effect in a previous paper (see Pfitzner, Lang, & Rishel, 2009) found that teams scored approximately 5.4 more points when the game was played in a closed dome stadium for the 2005-2006 season. However, for the 2010-2011 season, games played in domes averaged 45.4 points and games played outdoors averaged 44.3. That difference is not statistically significant; the t-test for independent samples yields a calculated value of 0.54. The dome effect may be idiosyncratic in that, in some seasons, the high scoring teams may happen to be those who play home games in domed stadiums.
The representative estimated equations (at the end of the 16th week) are given in Table II. For the home points equation, the passing yardage and the rushing yardage are significant at α < .01, and α < .05 levels, respectively. The equation explains a modest 4.2% ( ) of the variance in home points scored. On the other hand, the F-statistic indicates that the overall equation meets the test of significance at α < .01. The estimated coefficients for the variables have the anticipated signs. To interpret those coefficients, an additional 100 yards passing (recall that this is the sum of the home team’s passing offense and the visitor’s passing defense) implies approximately 4.3 additional points for the home team, whereas an additional 100 yards rushing implies approximately 4.2 additional points.
Table II: Regression Results for Total Points Scored
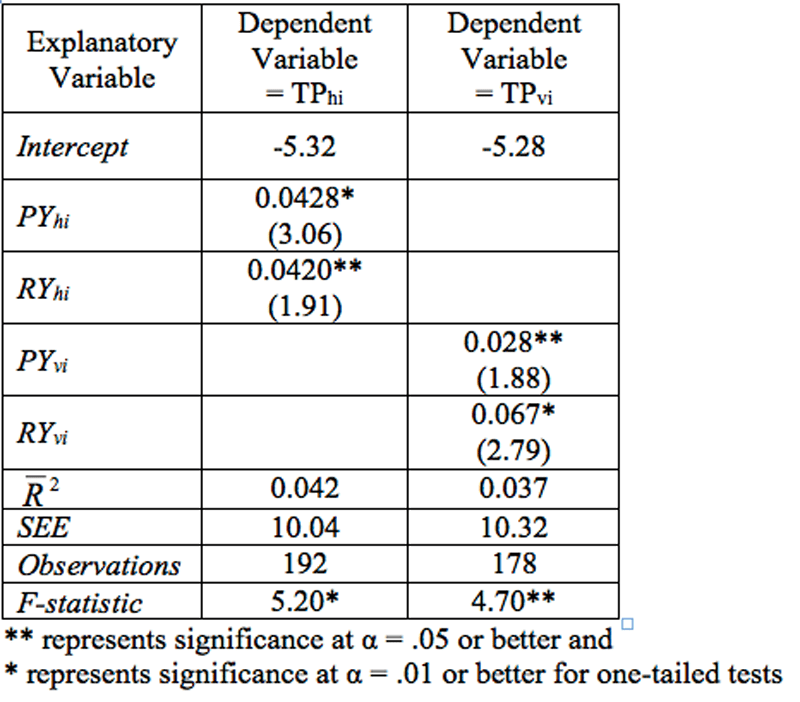
The visiting team estimation yields a similar equation in terms of the overall fit. The explanatory variables are statistically significant—the passing yardage variable at α < .05, and the rushing yardage variable is significant at α < .01. The equation explains only 3.7% ( ) of the variance in visiting team points, and the F-statistic implies overall significance at α < .05. The coefficients perhaps suggest a more important role for rushing than for passing in scoring for the visiting team. If the coefficients are to be believed, an additional 100 yards passing yields approximately 2.8 points for the visiting team, and an additional 100 yards rushing is worth 6.7 points.
The reader may find such low values to be of concern, but recognize that the variables for which we are attempting estimates are very difficult to predict and are subject to wide variation. As we show in a later section, the lines on the games are much easier to predict. The model is best judged by its prediction qualities—here based on wagering success.
Other Hypotheses
Another hypothesis we wished to entertain is whether or not scoring is contagious. A priori, we surmised that points scored in given games for visiting and home teams would be positively related. In keeping with our earlier work, there is no evidence that such is the case. The estimated simple correlation coefficient between home team and visiting team points is -0.106, which is not statistically different from zero and “wrong” signed according to our intuition. Our initial thinking was that if team “A” scores and perhaps takes a lead, team “B” has greater incentive to score. An obvious complicating factor is that a given team may dominate time of possession, thus preventing the opposing team opportunities to score. We also experimented with two-stage least squares to test the hypotheses that scoring was contagious. In that formulation we developed a “predicted points” variable for the home team, entered that variable as an independent variable in the visiting team equation, and reversed the procedure for the home team equation. Neither of the predicted points variables were statistically significant. The variable was positively signed for the home team equation, and negatively signed for the away team equation.
As indicated above, we also find no evidence that teams are “streaky” with respect to points scored. In short, we find that points scored in the immediately prior week do not contribute to the explanation of points scored in the current week. That conclusion holds up for the regressions in section VI as well.
Finally, though turnovers clearly matter in who wins or loses, there is no evidence from our work that measuring teams’ turnovers per game prior to the current game aids in predicting points scored by the individual teams.
Wagering on the Over/Under Line
In this simulated wagering project we use the estimated equations to predict scores of the home and away teams for all of the games played over weeks 8 through week 17 (end of the regular season). The points predicted in this manner are then compared to the over/under line for each game. We then simulate betting strategies on those games.
Out-of-Sample Method
Since it is widely known that betting strategies that yield profitable results “in sample,” are often failures in “out-of-sample” simulations, we use a sequentially updating regression technique for each week of games. Suppose, for example, we are predicting points for week 8. We then estimate equations TPhi and TPvi with the data from weeks 5, 6, and 7, then “feed” those equations with the known data for each game through the end of week 7, generating predicted points for the visiting and home team for all individual games in week 8. The predicted points are then totaled and compared to the over/under line for each game. Next we add the data from week 8, re-estimate equations TPhi and TPvi, and make predictions for week 9. The same updating procedure is then used to generate predictions for weeks 10 through 17. This method ensures that our results are not tainted with in-sample bias.
Betting Strategies
We entertain three betting strategies for the predicted points versus the over/under line on the games. These strategies are:
1. Bet only games for which our predicted total points differ from the line by more than 7 points.
2. Bet only games for which our predicted total points differ from the line by more than 5 points.
3. Bet all games for which our predicted total points differ from the line by any amount—in our case, all games.
As stated previously, a betting strategy on such games must predict correctly at least 52.4% of the time to be successful. If a given method cannot beat this 52.4% criterion, as a betting strategy it is deemed to be a failure.
Table III contains a summary of the results for the three betting strategies. The first betting strategy yields only ten “plays” over weeks 6 to 17. That betting strategy would have produced five wins, and five losses. For this (very) small sample, this strategy is, of course, not profitable, with only a 50% winning percentage. The second strategy (a differential greater than 5 points) yields 39 plays and a record of 17-10-0—a winning percentage of 63%. Finally for every game played, the method produces a still profitable record of 97-78-5, with the winning percentage at 55.4%.
Table III: Results of Different Betting Strategies
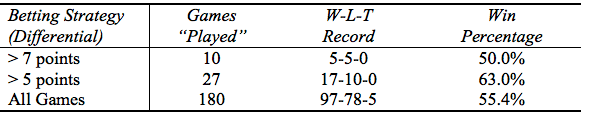
There is some consistency between these results and those we found for the 2005-2006 season. In that work we found that the “> 5 points” strategy produced a winning percentage of 60.5% based on 39 plays. Betting all games produced a winning percentage of 54%. Interestingly, the earlier research produced nine games with a greater than 10 point difference between the line and the predicted points whereas this work on 2010-2011 season produced only one play (which would have been a winning bet).
It is important to note that we make no adjustment for injuries, weather, and the like that would be considered by those who make other than simulated wagers. We offer these methods only as a guide, not as a final strategy.
Another Method of Predicting the Line and Total Points
Since we have collected and created variables that may be relevant to determining the betting line (and total points), in this section we investigate the relevancy of our variables in that context. For purposes of comparison, we estimate an equation for the over/under line and, separately, for the actual points scored. Further, we compare the results for the 2010-11 season with our results from prior research. These equations may be useful in confirming (or contradicting) the results of the previous sections, and may provide useful information applicable to wagering strategies.
The results of those regressions are contained in Table IV. We estimated regression equations for two seasons with the line as the dependent variable and all of the right-hand side variables (with the exception of turnovers) specified in equations 1 and 2. The estimations for the line are contained in the second column (2005-2006 season) and the fourth column (2010-2011 season). The estimations are remarkably similar. For the line for both seasons, every coefficient estimate is correctly signed and statistically significant at traditional levels of alpha, and for both equations. The line seems to be set on the assumption that teams are streaky (we conclude they are not), and the dome effect on the betting line seems to be a bit smaller in the most recent season.
Table IV: Regression Results for the Line and Total Points, 2005 and 2010 Seasons
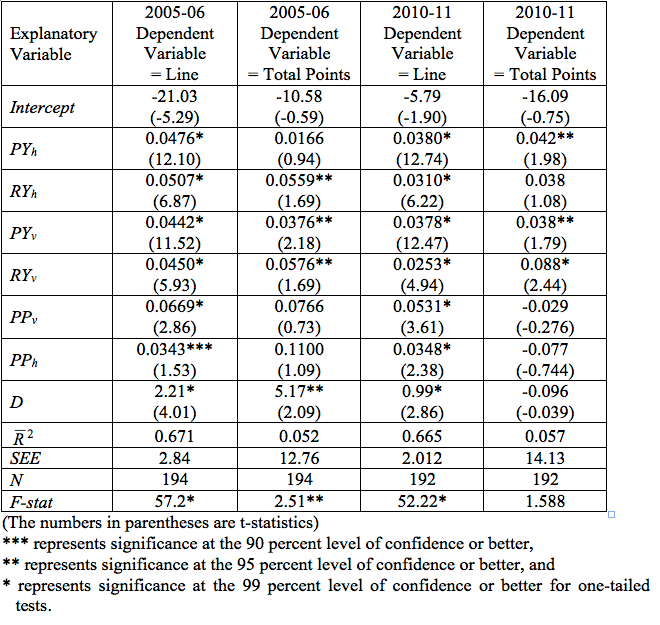
As a comparison, we also estimated (far less successfully) an equation for total points with the same set of explanatory variables with those results reported in columns three and five of Table IV. Perhaps the most striking result of these regressions is that the regressions for the line explain fully two-thirds of the variance in that dependent variable and the equations for the actual points explains less than 6% of the variance in total points for either season, with only four of the seven explanatory variables meeting the test for statistical significance at traditional levels for 2005-2006 and only three for 2010-2011. Interestingly, the dome effect for total points for the earlier season estimated 5 additional points scored in dome games, and the corresponding estimate for the 2010-11 season was zero, when controlling for other effects. Recall that for the 2005-2006 season, 5.4 points more were scored in games played in domes, and the corresponding difference was only one point for the 2010-2011 season.
In short, and to be expected, the line is much easier to predict than is actual points scored. That is, the outcome of the games and points scored therein are not easily predicted. It is tempting to say, “That’s why they play the games.” At least two further observations are in order. First, consider the coefficients for points scored in the previous game. Those variables matter as would be anticipated on an a priori basis in determining the line for the game. However, they seem to play an insignificant (statistical or practical) role determining the actual points scored. This particular result may be interpreted as bettors placing too much emphasis on recent information, as other authors have suggested.
Finally, it also seems clear that the effect of playing indoors has dissipated between the two seasons for which we report results in Table IV. As we have emphasized, this may be simply the effect of teams who play many games indoors having poorer scoring teams for any particular year.
CONCLUSIONS
The regression results in this paper identify promising estimating equations for points scored by the home and away teams in individual games based on information known prior to the games. In a regression framework, we apply the model to three simulated betting procedures for NFL games during weeks 6 through 17 of the 2010-2011 season. Betting strategies based on the differences between our predictions and the over/under line produced profitable results for either all games at any differential or those for which our predictions differed from the betting line by 5 or more points.
Based on our earlier results finding profitable wagering strategies for the 2005-2006 season, we (and others) questioned whether these results will hold up in other seasons. Based on the results presented here—so far, so good.
APPLICATIONS IN SPORT
Betting on sports, the NFL in particular, is a very popular pastime among sports (or gambling) enthusiasts and a very lucrative business for bookmakers in Las Vegas and elsewhere. This research was conducted to determine whether successful wagering strategies could be developed based on regression equations used to predict points for the home and away teams in individual games. The sum of the predictions for the home and away teams, updated weekly, were then compared to the over/under line on individual NFL games. Certain betting strategies were identified as successful, and could therefore be used by those wanting to improve their odds while enjoying and increasing their interest in America’s favorite sport.
ACKNOWLEDGMENTS
None
REFERENCES
1. Badarinathi, R., & Kochman, L. (2001). Football betting and the efficient market hypothesis. The American Economist, 40(2), 52-55.
2. Borghesi, R. (2007). The home team weather advantage and biases in the NFL betting market. Journal of Economics and Business, 59, 340-354.
3. Boulier, B. L., Steckler, H. O., & Amundson, S. (2006). Testing the efficiency of the National Football League betting market. Applied Economics, 38, 279-284.
4. Dare, W. H., & Holland, A. S. (2004). Efficiency in the NFL betting market: modifying and consolidating research methods. Applied Economics, 36, 9-15.
5. Dare, W. H., & MacDonald, S. S. (1996). A generalized model for testing home and favourite team advantage in point spread markets. Journal of Financial Economics, 40, 295-318.
6. Gray, P. K., & Gray, S. F. (1997). Testing market efficiency: Evidence from the NFL sports betting market. The Journal of Finance, LII(4), 1725-1737.
7. Levitt, S. D. (2002). How do markets function? An empirical analysis of gambling on the National Football League. National Bureau of Economic Research (Working Paper No. 9422).
8. Paul, R. J., & Weinbach, A. P. (2002). Market efficiency and a profitable betting rule: Evidence from totals on professional football. Journal of Sports Economics, 3, 256-263.
9. Pfitzner, C. B., Lang, S. D., & Rishel, T. D. (2009). The determinants of scoring in NFL games and beating the over/under ;ine. New York Economic Review, 40, 28-39.
10. Pfitzner, C. B., Lang, S. D., & Rishel, T. D. (2006). Can regression help to predict total points scored in NFL games? In A. Avery (Ed.), The 2006 Southeastern INFORMS Conference Proceedings (pp. 312-317). Myrtle Beach, SC: Southeastern INFORMS.
11. Vergin, R. C. (2001). Overreaction in the NFL point spread market. Applied Financial Economics, 11, 497-509.
